
Biostatistics and Bioinformatics
Biostatistics is the application of statistical methods and techniques to the study of biological phenomena and data. Biostatisticians work closely with biologists, epidemiologists, and other health researchers to design and analyze experiments, study data, and make inferences about the relationships between variables in biological systems.
Bioinformatics is the application of computational and statistical techniques to the management, analysis, and interpretation of biological data. Bioinformaticians work with large, complex data sets from sources such as DNA sequencing and gene expression experiments, and use a variety of tools and algorithms to extract insights and knowledge from the data.
Biostatistics and bioinformatics are closely related fields that both involve the use of statistical and computational methods for studying biological phenomena and data. Biostatistics focuses on the design and analysis of experiments and data, while bioinformatics focuses on the management, analysis, and interpretation of large, complex biological data sets.
Learn about the methods
Mixed Models
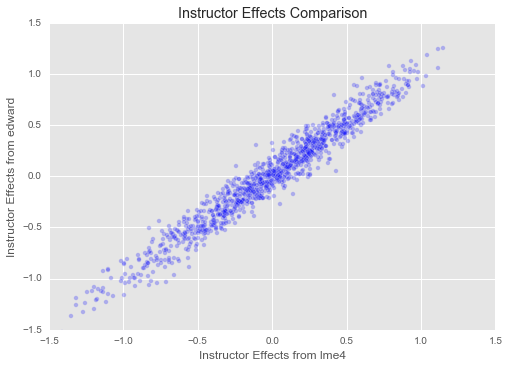
Mixed models are a type of statistical model that can be used to analyze data with both fixed and random effects. They are commonly used in biostatistics to account for the hierarchical structure of data, such as when individuals are nested within groups or when measurements are taken over time.
Mixed models allow for the estimation of both fixed and random effects, and provide a more efficient and accurate analysis of data with complex structures. They can be used to account for the correlation between observations within groups, to test for differences between groups, and to make predictions about future observations.
In summary, mixed models are a powerful tool in biostatistics for analyzing data with complex structures and accounting for both fixed and random effects. They can provide more accurate and efficient estimates of effects and help researchers make more informed conclusions about their data.
Linear and non linear mixed models
Linear mixed models and nonlinear mixed models are two types of statistical models that can be used in biostatistics to analyze data with both fixed and random effects. The main difference between the two is the type of relationship between the response and predictor variables.
Linear mixed models assume a linear relationship between the response and predictor variables, where the response is a linear combination of the predictors plus an error term. These models are commonly used when the relationship between the response and predictor variables is known or can be reasonably assumed to be linear.
Nonlinear mixed models, on the other hand, do not assume a linear relationship between the response and predictor variables. These models allow for more flexible and complex relationships between the variables, and are often used when the relationship is unknown or cannot be assumed to be linear.
In summary, the main difference between linear and nonlinear mixed models is the assumption about the relationship between the response and predictor variables. Linear mixed models assume a linear relationship, while nonlinear mixed models allow for more flexible and complex relationships.
Longitudinal Studies
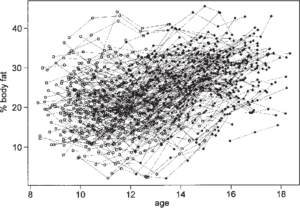
Longitudinal studies are a type of research study that involves collecting data from the same individuals over an extended period of time. These studies are commonly used in biostatistics to examine changes and trends in biological, behavioral, and health-related phenomena over time.
Longitudinal studies can provide valuable insights into the dynamic nature of biological systems and allow researchers to study the effects of time-varying exposures, treatments, and other factors on the outcome of interest. They can also help to identify factors that influence the development and progression of diseases and other health conditions.=
In summary, longitudinal studies are a powerful tool in biostatistics for studying changes and trends in biological, behavioral, and health-related phenomena over time. They can provide valuable insights into the dynamic nature of biological systems and help researchers to better understand the factors that influence health and disease.
Repeated Measures
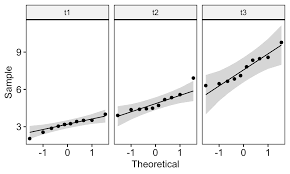
Repeated measures is a type of study design in which multiple measurements are taken on the same subjects over time or under different conditions. These studies are commonly used in biostatistics to assess the effects of interventions or treatments on a particular outcome, or to investigate changes in a variable over time.
Repeated measures studies can provide valuable insights into the relationship between the variable of interest and the intervention or treatment, and can help researchers make more informed conclusions about their data. However, these studies also present unique statistical challenges, such as the need to account for the dependence between the repeated measurements and the potential for carryover effects.
In summary, repeated measures is a common study design in biostatistics that involves taking multiple measurements on the same subjects over time or under different conditions. These studies can provide valuable insights into the effects of interventions or treatments, but also present unique statistical challenges.